

A deep dive into the impact of automation and technology on jobs
 Steve
SteveI spent some time over the weekend, (I know, I probably need some other hobbies), reviewing a new report from the Brookings Institute titled 'Automation and Artificial Intelligence: How Machines are Affecting People and Places'. In the report, Brookings sought to examine (like plenty of other organizations in the last few years), what the potential impact of advanced technologies, automation, and AI will be on the labor market. Mainly, which kinds of jobs and in what areas are more or less likely to be affected, changed, and potentially replaced as technology continues to improve and advance.
There is a ton of interesting information in the 100+ page report, and for those of you who are interested in this sort of thing, I would block some time to go through it all, but for those who may want a shorter, TL;DR version, here are what are to me, the three most interesting findings/conclusions/takeaways from the report.
1. Contrary to a lot of hype and hysteria around automation and AI, most jobs are not highly susceptible to automation. Take a look at the key finding from Brookings in the chart below:
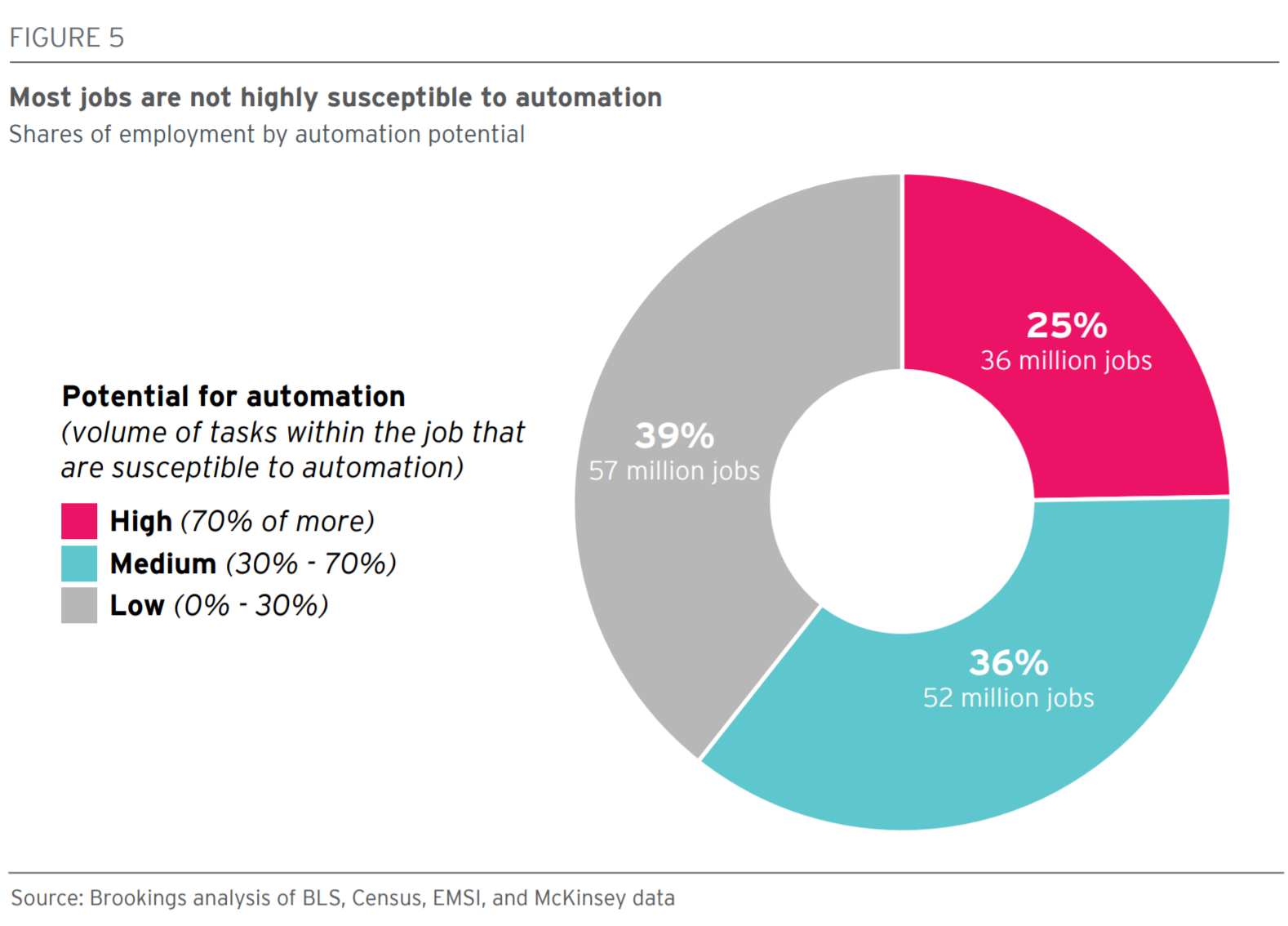
While almost no single occupation will be completely unaffected by the adoption of new technology, the impact on jobs will be of varying intensity and significant for only about 25% of jobs. Another 52 million or so jobs, about 36% of the labor force will see some or medium impact from new tech. And another 39% of jobs will only see a low impact from new technology. This disparate impact on jobs reminds me of the old saying, 'The future has already arrived, it's just not evenly distributed'.
2. Lower wage jobs are, on average, more exposed to potential automation. Within the variability expressed in the first chart, Brookings tries to break down what kinds of jobs, at what kind of wages, and in which geographic areas are most prone to be impacted by technology. Here's a look at the data around wage level and potential impact from automation:

The main driver behind lower wage jobs being more susceptible to automation is the tendency for jobs made up largely of routine, predictable physical and cognitive tasks are the ones most vulnerable to automation in the short and medium term. Think jobs like office administration, simple production, and food preparation. So according to Brookings the roles that now tend to pay the lowest wages are at the most risk. The danger of this of course is that the people holding these jobs also tend to be the least prepared to make a job shift into roles that are more complex, higher up the wage scale, and less likely to be impacted by technology.
3. In addition to varying widely across types of jobs and wage level, automation of jobs is likely to vary widely by location as well. The larger relative impact will be felt, according to Brookings, in smaller, and more rural areas. See the data below:
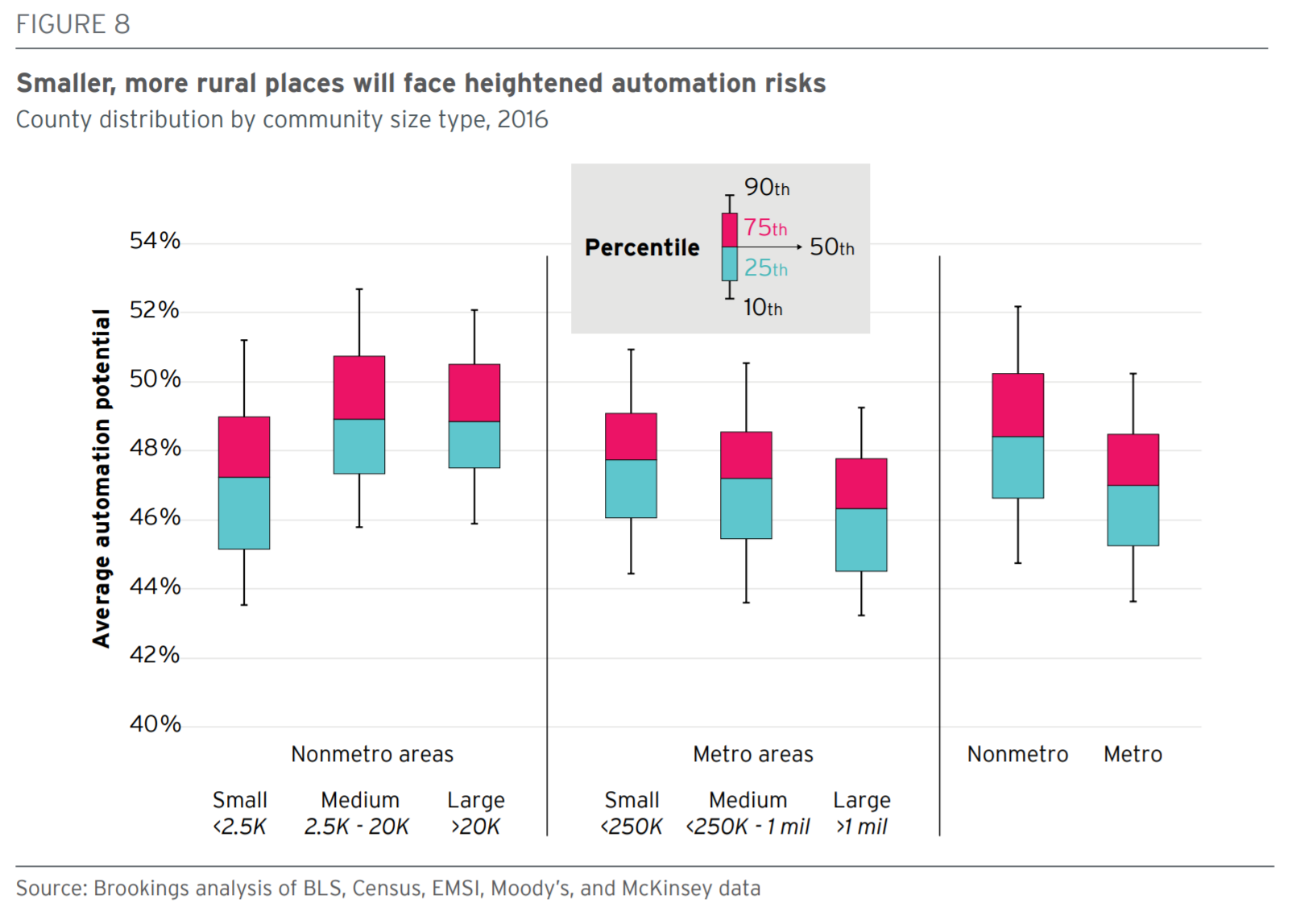
There's a lot of detailed data to parse through there, but basically workers in smaller and more rural communities are about 10 percentage points more likely to have their jobs adversely impacted by technology than workers in urban areas. This could be a by-product of the continuing challenge that smaller communities have in keeping their skilled and younger workers from leaving to seek better opportunities in larger towns and cities.
Since this is a long post already, I will leave covering what the folks at Brookings suggest can be done by localities, companies, education, and people in order to be better prepared for the ongoing waves of automation. Suffice to say though that understanding the problem and challenge is the important first step to solving it.
Take some time to look at the whole report if you can.
Have a great week!



