CHART OF THE DAY: There are more job openings in the USA than ever
 Steve
SteveI know I have written a couple of versions of this post in the last year or so, but to me, and as the data referenced in the post title keeps increasing, I think it is worth taking a look at the latest job openings data.
As always courtesy of our pals at the BLS and using the fantastic charting capability from the St. Louis Fed.
Here's the chart showing the total number of non-farm job openings in the US over the last 10 years or so and hen some words of wisdom and whimsy from me as we get ready to head into the weekend.
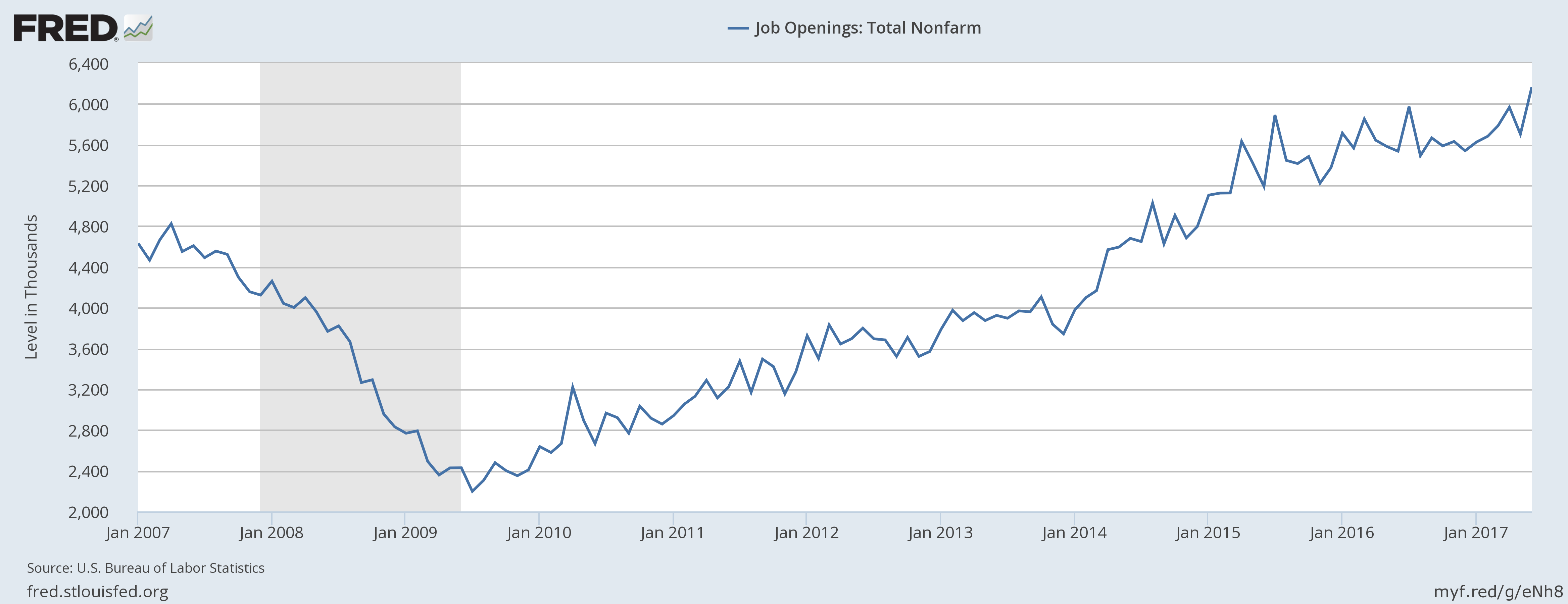
Three quick takes...
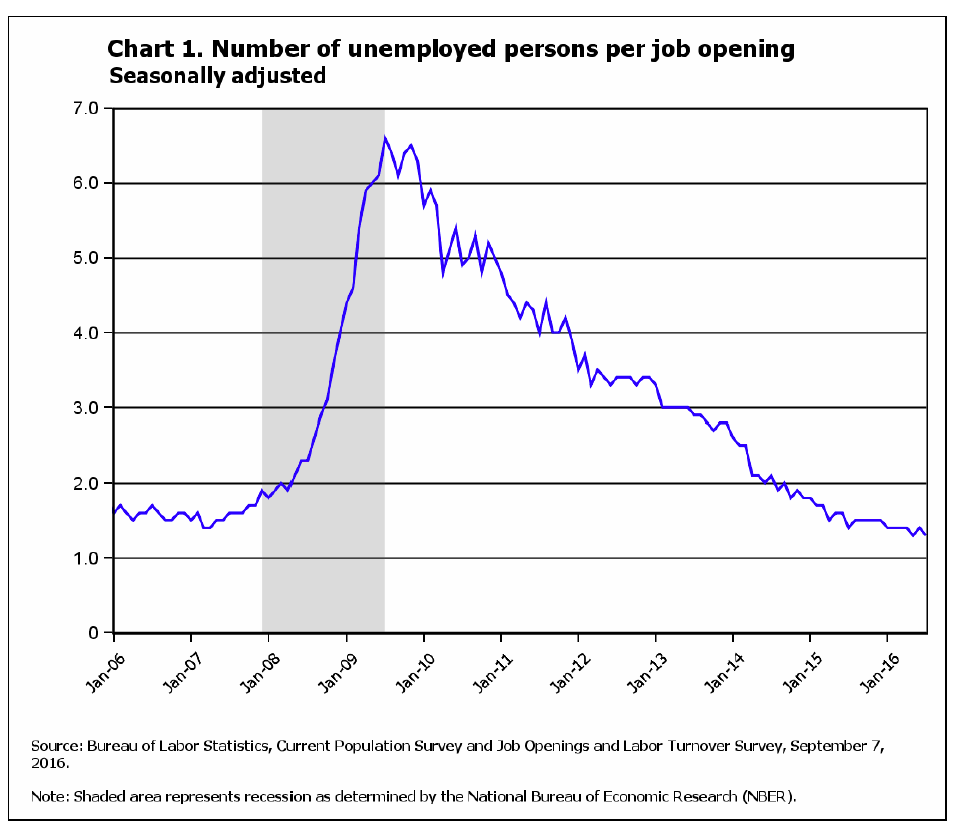
1. It may be hard to see on the chart, but the end of June 2017 data point shows a whopping 6.2 million open jobs in the USA. That is the record high for this measurement since records began to be kept starting in 2000. To give the 6.2 million number a little context, the total US labor force at the end of June is just over 160 million. Said differently, if we could magically fill the 6.2 million openings today, total US employment would jump almost 4%. That is a huge, huge number when talking about this kind of data.
2. Wages, while growing, are not yet, (maybe never?), catch up to the fact that job openings keep increasing and time to fill metrics also continue to climb. I caught a quote from a random Fed official recently, can't remember which one at the moment, that essentally said something like 'If your business has a hiring problem or you think you have a 'skills gap' problem, and you have not taken steps to meaningfully increase wages and benefits you are offering, then I just don't believe you actually have a problem.' Persistent sluggish wage growth has been the most baffling element of the sustained labor market recovery of the last several years.
3. I know this is obvious, and I know I have blogged this bit a few times before when considering the tight labor market, but it bears repeating. More and more power is shifting to employees, candidates, graduates - almost anyone with up to date skills and a desire to succeed. Factor in the myriad ways for people to side hustle, and employers have to continued to raise their game and their value props to have any chance of staying competitive in today's market. I am a 'labor' guy at heart, and more leverage and negotiating power shifting to workers just feels like a decent thing to me.
Have a great weekend all!